Have you ever looked at the sheer size of today's top AI models and wondered, "How on earth can this keep scaling?" It feels like we're in an arms race where bigger is always better, but that comes with astronomical compute costs and energy bills. It’s a real problem.
What if there was a different way? A "smarter, not harder" approach to building massive AI?
Well, it looks like the Inclusion AI team over at Ant Group is thinking along the same lines. They've just released Ling 2.0, a family of language models built on a fascinating principle: what if you could grow a model's total knowledge to massive scales, but keep the amount of work it does for any single task pretty much the same? It's a method that lets them scale from a 16 billion parameter model all the way up to a trillion without having to reinvent the wheel each time.
Let's break down what they're doing, because I think it’s a really elegant solution to one of AI's biggest challenges.
The Secret Sauce: A "Mixture of Experts"
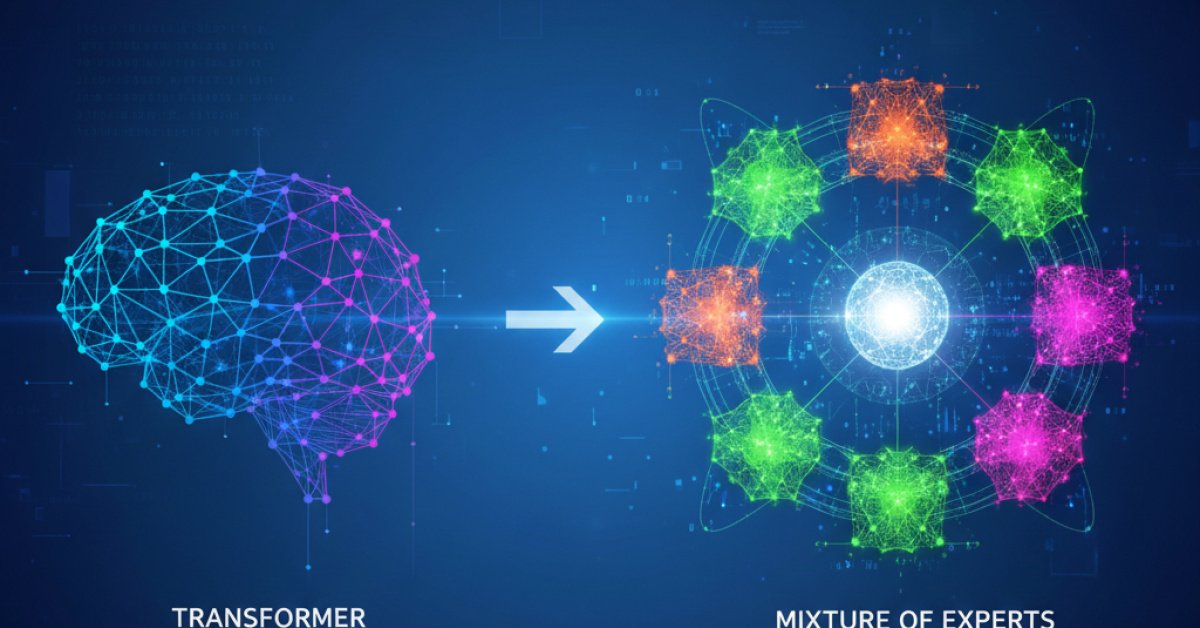
At the heart of every Ling 2.0 model is something called a sparse Mixture of Experts, or MoE, architecture.
Think of it like this. A traditional "dense" model is like a single, giant brain that has to process every single piece of information. It's powerful, but it’s also inefficient. For every word you feed it, the entire brain lights up.
An MoE model, on the other hand, is more like a team of specialized consultants. Instead of one giant brain, Ling 2.0 has a pool of 257 "experts" in each layer. One of these is a "shared expert," like a general manager who's always involved. The other 256 are specialists.
When you give the model a token (basically a word or part of a word), a smart router looks at it and says, "Okay, for this specific task, I need these 8 specialists." So, for any given token, only 9 experts (the 8 specialists + the 1 general manager) get to work. That’s just 9 out of 257, or about 3.5% of the total capacity.
This is the magic of sparsity. The model has this huge pool of knowledge (parameters) to draw from, but it only activates a tiny fraction of it at any moment. The Ant Group team says this makes their models about seven times more efficient than a dense model of a similar capability. You get the power of a massive network without the massive compute cost for every single token.
The Four-Layer Blueprint for Building a Smarter AI
So, how did they pull this off? It wasn't just about plugging in an MoE layer and calling it a day. Ling 2.0 is the result of coordinated work across the entire stack, from the model's design all the way down to the hardware it runs on.
1. The Architecture: No Guesswork Allowed
Instead of just guessing what might work, the team used something they call "Ling Scaling Laws." To develop these laws, they run a "Ling Wind Tunnel"—a series of small, cheap-to-train MoE models. By analyzing how these little models perform, they can create power-law formulas that accurately predict how a much, much larger version will behave.
It’s brilliant, really. It's like building a perfect scale model of a skyscraper and testing it in a wind tunnel to find design flaws before you spend billions on the real thing.
This process is what led them to the magic numbers: 256 routed experts, 1 shared expert, and an activation ratio of 1-in-32 (which is where that ~3.5% comes from). Because they used the same "laws" to design all three models in the family, their performance scales predictably from the smallest to the largest version.
2. The Training: Baking in Reasoning from the Start
You can't just build a smart architecture and feed it junk. The Ling 2.0 series was trained on a massive dataset of over 20 trillion tokens. But it’s how they fed it the data that’s interesting.
They started with a 4K context window and a general mix of data. But as training progressed, they gradually increased the proportion of reasoning-heavy content like math and code until it made up almost half the data.
Later, they did a mid-training stage to stretch the context window to 32K, then injected another 600 billion tokens of high-quality "chain of thought" examples. Finally, they pushed the context all the way to 128K. By doing this in stages, they ensured that reasoning and long-context capabilities were fundamental parts of the model, not just features tacked on at the end.
3. The Alignment: Teaching It to Think and Talk
After the initial training, the model needs to be aligned with human expectations. The team split this into two main phases:
- Capability Pass: First, they used a technique called Decoupled Fine-Tuning to teach the model how to switch between giving a quick, simple answer and providing a deep, reasoned one, based on the system prompt. It learns to recognize when a user needs a simple fact versus a complex explanation.
- Preference Pass: Next, they used an evolutionary method to generate diverse and complex chains of thought. Then, they used a fine-grained reward system to align the model’s outputs with what humans actually prefer, sentence by sentence.
This staged process is what allows the base model to become incredibly good at math, code, and following instructions without bloating every single answer with unnecessary reasoning.
4. The Infrastructure: Making It All Practical
Building a trillion-parameter model is one thing; training it without breaking the bank is another. The team made some smart choices on the systems side.
Ling 2.0 is trained natively in FP8, a number format that’s less precise than the standard BF16 but offers a nice ~15% performance boost. But the really big speedups, around 40%, came from clever engineering like heterogeneous pipeline parallelism—basically, a smarter way to schedule and partition the work across the GPUs.
They also used a cool technique called "Warmup Stable Merge," which involves merging checkpoints instead of using traditional learning rate decay. All these system-level optimizations are what make training a model at this massive scale actually feasible on existing hardware.
So, How Do the Models Stack Up?
The results are pretty consistent and prove the concept works. The sparse MoE models deliver really competitive performance while keeping that per-token compute cost incredibly low.
Here’s a look at the family:
- Ling mini 2.0: This is the smallest, with 16 billion total parameters, but it only activates 1.4 billion per token. The team reports that it performs on par with dense models in the 7-8 billion parameter range. On simple Q&A tasks, it can generate over 300 tokens per second, which is impressively fast.
- Ling flash 2.0: This one is in the 100 billion parameter class and activates 6.1 billion per token. It uses the exact same 1/32 activation recipe, showing that the design scales up nicely. It gives you a much higher capacity without making inference slower.
- Ling 1T: This is the flagship, the proof that the whole design holds up at the trillion-parameter scale. It has about 50 billion active parameters per token, maintaining that same sparsity. This is the model that packs in the 128K context window and the advanced alignment training to really push the boundaries of efficient reasoning.
What This Means for the Future of AI
For me, this release is more than just another new model. It’s a clear and compelling demonstration of a complete, end-to-end sparse MoE system that actually works and scales.
The Ling 2.0 series shows us a path forward where we don't have to just keep building bigger, denser, and more power-hungry models. By using a predictable scaling recipe, they’ve proven you can lock in an efficient architecture and use it to build everything from a nimble small model to a massive reasoning engine.
It’s a strong signal that the future of trillion-scale AI might not be monolithic giants, but rather these incredibly vast yet efficient networks of specialists. It’s a more sustainable, and frankly, a more elegant way to scale intelligence. And that’s something we can all get excited about.