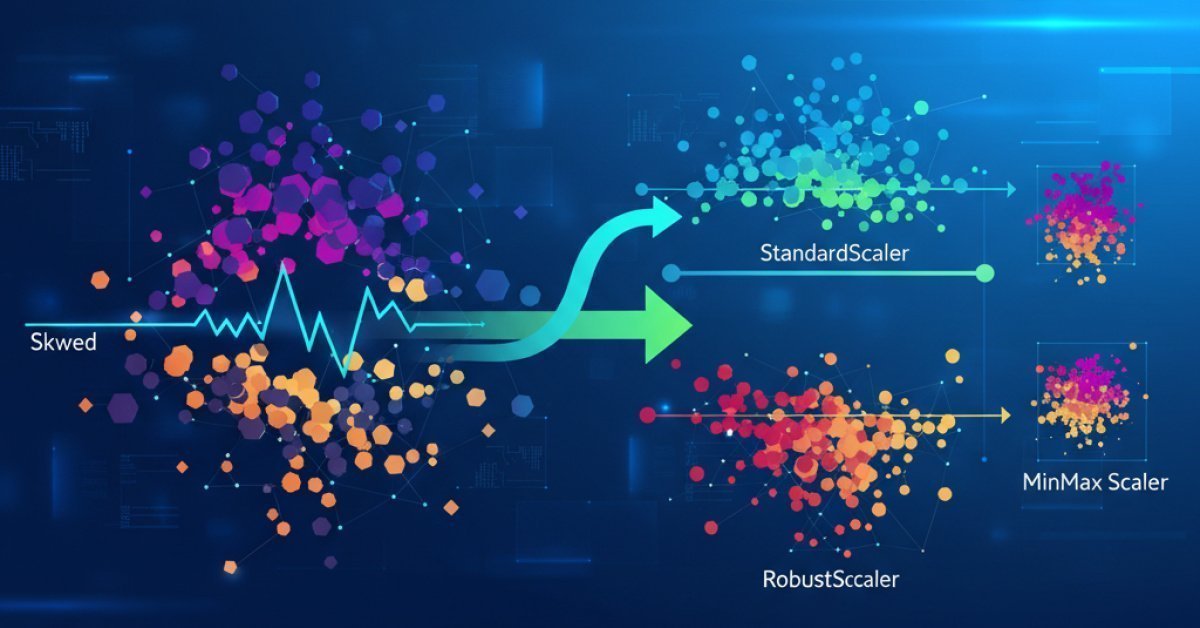
So, you’ve done the hard work. You’ve wrangled your data, cleaned it up, and you're ready to feed it to your shiny new machine learning model. You fire up your notebook, plot a few histograms to admire your handiwork, and... yikes. The distributions look less like a gentle bell curve and more like a skateboard ramp, with a long, ugly tail stretching out to one side.
This is skewed data, and it's the bane of many data scientists' existence. Features like income, house prices, or website visits per user often look like this. A few extreme values—the billionaires, the mega-mansions, the viral posts—pull the average way out, making the data tricky to work with.
If you ignore this and push forward, many models will get confused. Algorithms that rely on distances (like K-Nearest Neighbors or SVMs) or assume normality (like Linear Regression) can give far too much weight to these outlier-driven features. The result? A model that performs poorly. The solution is feature scaling, but now you have a new problem: which scaler is the right tool for this very specific, very messy job?
First Things First: Why Do We Even Need to Scale Data?
Before we pit our scalers against each other, let's quickly recap why we're here in the first place. Imagine you're building a model to predict house prices, and you have two features: the number of bedrooms (ranging from 1 to 5) and the square footage (ranging from 800 to 5,000).
To a distance-based algorithm, a change of 1,000 in square footage looks monumental compared to a change of 1 in the number of bedrooms. The model will naturally assume square footage is vastly more important, not because it is, but simply because its numbers are bigger. It's an "apples and oranges" problem that can completely throw off your model's learning process.
Feature scaling solves this by putting all your features on a level playing field. It transforms them so they share a common scale, ensuring no single feature dominates just because of its arbitrary units. It’s a non-negotiable step for many of the most powerful algorithms in our toolkit.
Meet the Contenders: A Breakdown of the Big Three
When you open up Scikit-learn, you're faced with a few popular choices for scaling. Let's get to know the three most common ones and, more importantly, understand their fatal flaws when it comes to skewed data.
The Old Faithful: StandardScaler
StandardScaler is probably the first scaler most of us learn. It's the default choice in countless tutorials and for good reason—it's robust and effective for "well-behaved" data.
How it works: It transforms each feature by subtracting the mean and then dividing by the standard deviation. This process, called standardization, centers the data around a mean of 0 and a standard deviation of 1.
The catch: Its entire calculation is based on the mean and the standard deviation. And what are the two statistical measures most notoriously sensitive to outliers? You guessed it: the mean and the standard deviation.
If you have a right-skewed feature like salary, a few multi-million dollar earners will drag the mean way up. When StandardScaler uses this inflated mean to center your data, the bulk of your "normal" salaries will end up being negative, and the outliers will still be massive positive numbers. You’ve scaled the data, but you haven't really fixed the underlying issue caused by the skew.
The Squeezer: MinMaxScaler
Next up is MinMaxScaler. This one is conceptually even simpler. It takes every data point and squishes it into a specific range, most commonly between 0 and 1.
How it works: It finds the minimum and maximum values in your feature and uses them to re-scale everything. The formula is straightforward: (value - min) / (max - min). The smallest value becomes 0, the largest becomes 1, and everything else falls somewhere in between.
The catch: Its entire logic is dictated by just two points: the absolute minimum and the absolute maximum. If your dataset has even one extreme outlier, it can completely ruin your scaling.
Imagine scaling a feature for house prices in a normal neighborhood, but one sale was for a celebrity's $50 million compound. That $50 million mansion becomes your max value (scaled to 1.0). A perfectly normal $400,000 house might get scaled down to something like 0.008. All the meaningful variance between the normal houses gets compressed into a tiny fraction of the range, rendering the feature almost useless.
The Unsung Hero: RobustScaler
This brings us to the one you might have overlooked. As its name suggests, RobustScaler is built to be, well, robust to outliers. It doesn't get easily flustered by those extreme values that throw the other two scalers into a tailspin.
How it works: Instead of the mean and standard deviation, RobustScaler uses the median and the Interquartile Range (IQR). The IQR is the range between the 1st quartile (25th percentile) and the 3rd quartile (75th percentile), which represents the bulk of your data.
It works by subtracting the median from each data point and then dividing by the IQR.
Why this is a game-changer: The median and IQR are brilliant because they essentially ignore the outliers. The median of [1, 2, 3, 4, 100] is 3, completely unbothered by that 100. By using these resistant metrics, RobustScaler focuses on the central tendency of your data, scaling the majority of your points properly. The outliers will still be there—they'll just be very large or very small numbers—but they won't have corrupted the scaling process for everything else.
The Showdown: Which Scaler Actually Wins for Skewed Data?
Let's make this crystal clear. When your data is skewed, it almost always implies the presence of outliers that are pulling the tail. In this scenario, there's a clear winner.
It's RobustScaler, and it's not even close.
Let’s walk through what happens to your skewed "income" data with each scaler:
- With StandardScaler: The high-income outliers pull the mean to the right. After scaling, most people will have a negative income, and the wealthy few will have large positive values. The distribution is still skewed.
- With MinMaxScaler: That one CEO making $20 million a year becomes the
maxvalue of 1. Everyone else, from interns to senior managers, gets squashed into a tiny range like 0 to 0.05. You've lost all the valuable information in the majority of your data. - With RobustScaler: It finds the median income, which is a much more realistic representation of the "typical" person. It scales the data around this median using the IQR. The result? The bulk of the incomes are nicely distributed around 0, and the outliers are kept as extreme values that don't mess up the scale for everyone else.
For skewed data, RobustScaler preserves the structure of your inlier data, which is exactly what you want your model to learn from.
So, Are the Other Scalers Useless?
Absolutely not! Choosing a scaler is all about context. While RobustScaler is the champion for skewed data, the others have their own arenas where they shine.
When should you use StandardScaler? It's the perfect tool for data that is already normally distributed or at least symmetrical. If your feature plots look like a nice bell curve without any crazy outliers, StandardScaler is efficient, effective, and often the best choice. It's a fantastic general-purpose scaler for clean data.
When should you use MinMaxScaler? MinMaxScaler is your go-to when you absolutely need your data to be within a strict boundary, like [0, 1]. This is incredibly common in two main areas:
- Image Processing: Pixel intensities are often scaled from [0, 255] down to [0, 1] for neural networks.
- Neural Networks: Some activation functions, like the sigmoid or tanh, are sensitive to the input range and perform best with small, bounded values.
If you use MinMaxScaler, just make sure you've either confirmed you don't have extreme outliers or you've already dealt with them through another method (like clipping or removal).
A Simple, Actionable Workflow for Scaling
Feeling more confident? Let's tie it all together into a simple process you can follow every time you start a new project.
- Always, Always Visualize First: Before you even think about writing
scaler.fit_transform(), plot your data. Histograms and box plots are your best friends. They will instantly reveal skewness and outliers. Don't scale blindly. - Assess the Distribution: Look at your plots. Is the data roughly symmetrical like a bell? Or does it have a long tail? Are there dots in your box plot miles away from the whiskers?
- Choose Your Scaler Wisely:
- Heavy Skew / Obvious Outliers? Go straight for RobustScaler. It’s designed for this exact problem.
- Fairly Symmetrical / Gaussian-like? Stick with the classic StandardScaler. It's the industry standard for a reason.
- Need Data in a [0, 1] Range (and outliers are handled)? Use MinMaxScaler.
- Prevent Data Leakage: This is a critical final step. You must only
fityour scaler on the training data. This learns the median and IQR (or mean/std) from the training set. Then, you use that same fitted scaler totransformboth your training data and your test data. Fitting on the whole dataset before splitting is a common mistake that leaks information from your test set into your training process, giving you overly optimistic results.
By following this thought process, you're no longer just picking a scaler at random. You're making an informed, data-driven decision that will respect the integrity of your data and give your machine learning models the best possible chance to succeed.